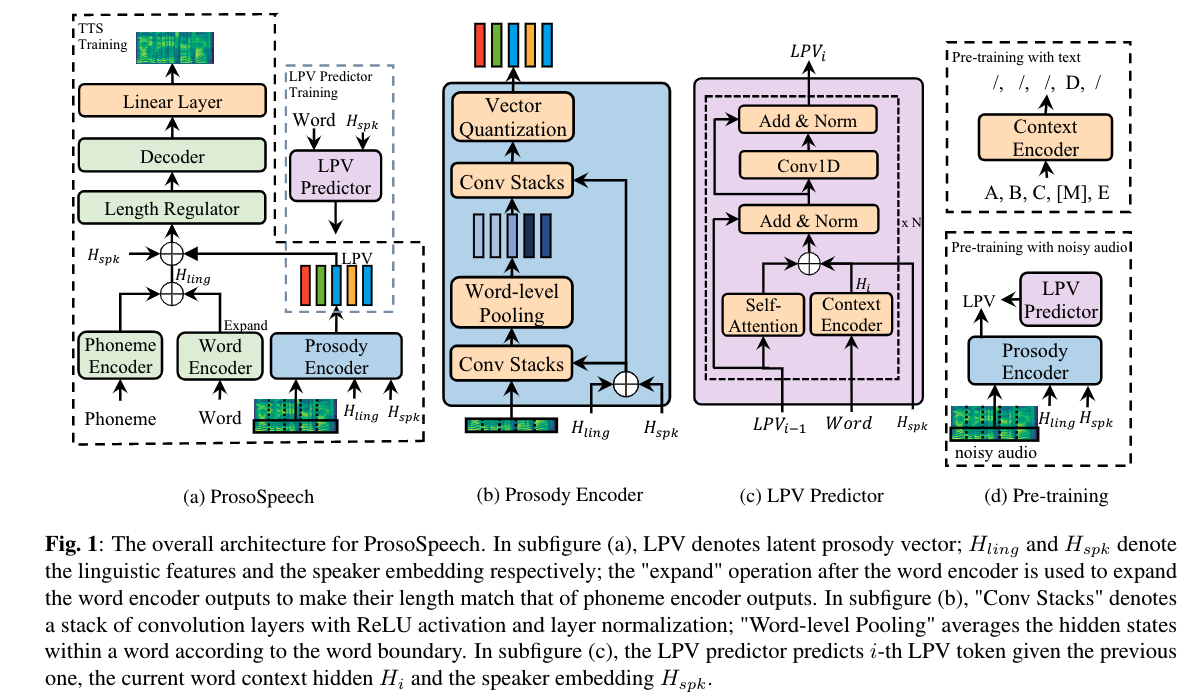
Expressive text-to-speech (TTS) has become a hot research topic recently, mainly focusing on modeling prosody in speech. Prosody modeling has several challenges: 1) the extracted pitch used in previous prosody modeling works have inevitable errors, which hurts the prosody modeling; 2) different attributes of prosody (e.g., pitch, duration and energy) are dependent on each other and produce the nature prosody together; and 3) due to high variability of prosody and the limited amount of high-quality data for TTS training, the distribution of prosody cannot be fully shaped. To tackle these issues, we propose ProsoSpeech, which enhances the prosody using quantized latent vectors pre-trained on large-scale unpaired and low-quality text and speech data. Specifically, we first introduce a word-level prosody encoder, which quantizes the low-frequency band of the speech and compresses prosody attributes in the latent prosody vector (LPV). Then we introduce an LPV predictor, which predicts LPV given word sequence. We pre-train the LPV predictor on large-scale text and low-quality speech data and fine-tune it on the high-quality TTS dataset. Finally, our model can generate expressive speech conditioned on the predicted LPV. Experimental results show that ProsoSpeech can generate speech with richer prosody compared with baseline methods.
Audio Samples
- 亨利街的北侧便是莎翁故居。
GT GT(voc.) FastSpeech FastSpeech 2 FastSpeech (joint) wav ProsoSpeech w/o text PT w/o audio PT w/o text/audio PT wav - 众所周知,潍坊因风筝而在全国闻名遐迩。
GT GT(voc.) FastSpeech FastSpeech 2 FastSpeech (joint) wav ProsoSpeech w/o text PT w/o audio PT w/o text/audio PT wav - 傻傻的乱叫,什么也不敢动。
GT GT(voc.) FastSpeech FastSpeech 2 FastSpeech (joint) wav ProsoSpeech w/o text PT w/o audio PT w/o text/audio PT wav - 努尔始终咬紧牙关,不哭也不说话。
GT GT(voc.) FastSpeech FastSpeech 2 FastSpeech (joint) wav ProsoSpeech w/o text PT w/o audio PT w/o text/audio PT wav